Python で統計解析 (SciPy, Pylab, NumPy)
Matlab を覚えるより、今なら Python でもお手軽に統計解析ができます。
データ入出力も可視化も Python 文法でできてお手軽です。
意外と Windows での環境構築も楽々でした。
パッケージの紹介
ここでは、NumPy, SciPy, PyLab (Matplotlib) の3つのパッケージを使います。
NumPy が基本の数値演算、SciPy がもう少し進んだ統計処理、PyLab が動的にグラフを描く GUI を提供します。
これら数値演算パッケージでは、専用の配列を確保する命令や、平均や分散の計算、 行列演算などの統計処理を高速で行う命令が入っています。 標準の Python でも同じことはできますが、NumPy / SciPy を使ったほうが高速に処理できます。
NumPy と SciPy は数値演算を行うだけで、Windows 向けのバイナリも提供されています。 一方、PyLab は上記2つに比べると用途が限られるので、Windows での利用は少しハードルが高そうです。
これら数値演算パッケージでは、専用の配列を確保する命令や、平均や分散の計算、 行列演算などの統計処理を高速で行う命令が入っています。 標準の Python でも同じことはできますが、NumPy / SciPy を使ったほうが高速に処理できます。
NumPy と SciPy は数値演算を行うだけで、Windows 向けのバイナリも提供されています。 一方、PyLab は上記2つに比べると用途が限られるので、Windows での利用は少しハードルが高そうです。
Windows 向けインストール
Python のライブラリはハードウェア/OS 非依存で書くこともできますが、
SciPy は高速な処理を行うため、ハードウェア/OS 依存のネイティブコードを
含んで実装されています。
ですので、パッケージは Windows の x86 または x86-64 (amd86) 向けにビルドされたものを探してきてインストールします。
まず、Python を入れます。バージョンは 3.x ではなく、2.7 がお勧めです。 Python のダウンロードページから、Python 2.7.x Windows X86-64 Installer をダウンロードしてインストールします。
次に、UCI の非公式 Windows 向けバイナリ配布ページから、NumPy (numpy-MKL-1.7.0rc1.win-amd64-py2.7.exe) と、SciPy (scipy-0.11.0.win-amd64-py2.7.exe) をダウンロードしてインストールします。
最後に、PyLab (Matplotlib) をインストールします。 Matplotlib のダウンロードページから、Python 2.7 - Windows - amd64 版 (matplotlib-1.2.0.win-amd64-py2.7.exe) を選んでダウンロードしてインストールします。
これでインストールは完了です。スタートメニューの Python27 の中から IDLE (Python GUI) を選択して、以下のコマンドを試します。エラーがでなければ成功です。
まず、Python を入れます。バージョンは 3.x ではなく、2.7 がお勧めです。 Python のダウンロードページから、Python 2.7.x Windows X86-64 Installer をダウンロードしてインストールします。
次に、UCI の非公式 Windows 向けバイナリ配布ページから、NumPy (numpy-MKL-1.7.0rc1.win-amd64-py2.7.exe) と、SciPy (scipy-0.11.0.win-amd64-py2.7.exe) をダウンロードしてインストールします。
最後に、PyLab (Matplotlib) をインストールします。 Matplotlib のダウンロードページから、Python 2.7 - Windows - amd64 版 (matplotlib-1.2.0.win-amd64-py2.7.exe) を選んでダウンロードしてインストールします。
これでインストールは完了です。スタートメニューの Python27 の中から IDLE (Python GUI) を選択して、以下のコマンドを試します。エラーがでなければ成功です。
import numpy import scipy import pylab以下の説明は、すべて上記の準備が終わった状態 (Python IDLE を起動して、import が終わった状態) から初めます。
Linux 向けインストール
Linux の場合はビルドする場合もしない場合も、概して簡単です。
例えば Ubuntu の場合は、以下のコマンドで楽々インストールできます。
例えば Ubuntu の場合は、以下のコマンドで楽々インストールできます。
$ sudo apt-get install python-scipy $ sudo apt-get install python-matplotlib
とりあえず Numpy 配列を作る
NumPy/SciPy での処理には、NumPy 配列を使います。
とりあえず使ってみるにも必須なので、まずは配列の作り方から初めます。
-
ふつうの配列からの変換。
>>> my_array = [0,1,2] >>> numpy.array(my_array) array([0, 1, 2])
これで NumPy 配列が作成できました。
NumPy 配列は掛け算ができます。>>> a = numpy.array([0,1,2]) >>> a * 2 array([0,2,4])
二次元配列も作れます。>>> numpy.array([[1,2], [3,4]])
-
0 から 1 まで 0.2 刻みの配列を作成。
>>> numpy.arange(-1, 1, 0.2) array([ 0., 0.2, 0.4, 0.6, 0.8])
-
乱数配列を生成してみます。
a = numpy.random.ranf(3)
a を表示すると、長さ 3 の配列になっています。 -
ガウス関数の乱数配列を生成してみます。
>>> numpy.random.random(0, 1, 3) array([-1.3596169 , 0.12789815, 0.44725795])
中心が 0 、幅が 1 の乱数が 3 つできました。
二次元配列も作れます。>>> numpy.random.multivariate_random([0,0], [[2,1], [1,2]] , 10)
中心が [0,0] 、幅が [2,1] と [1,2] 方向に分散した、長さ 10 の配列ができます。
PyLab で点を描画してみる
数値をいじっていてもイメージが掴みづらいので、PyLab を使ってグラフにしてみます。
(PyLab が入っていない人は飛ばしてください)
まず import します。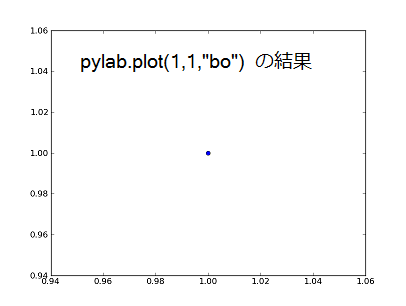 最後の "bo" が青 ('b'lue) の丸 (o) を示しています。
最後の "bo" が青 ('b'lue) の丸 (o) を示しています。
次に、[2,3] を赤い X で描画してみます。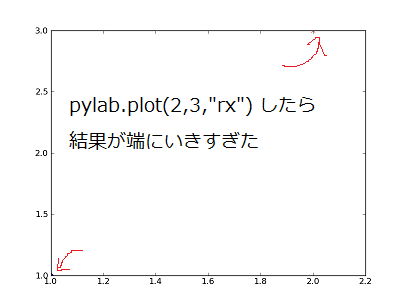
最後の "rx" が赤 ('r'ed) の X 印 (x) を示しています。
ですが、軸がぎりぎりになってしまい、点が右上と左下に隠れてしまいました。 (赤い矢印で示したところにあります)
そこで、x, y の範囲をどちらも 0 - 4 に設定してみます。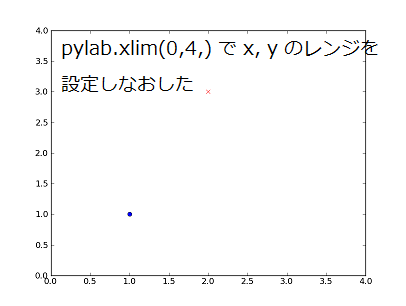
これで、正しく表示されるようになりました。
一度表示をクリアする場合は、以下のコマンドを呼びます。
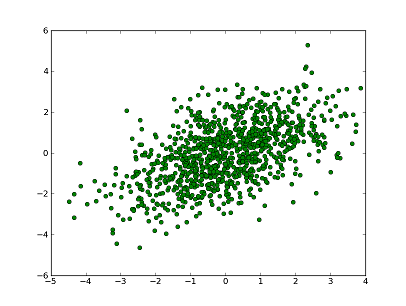
もっと一気にたくさん点を描画してみます。 先ほど二次元の乱数を生成したので、それを plot してみます。
まず import します。
import pylabここで扱うグラフは通例 2 次元です。 点 [1,1] を青い丸で描画してみます。
pylab.plot(1, 1, "bo") pylab.show()
最後の "bo" が青 ('b'lue) の丸 (o) を示しています。
次に、[2,3] を赤い X で描画してみます。
pylab.plot(2, 3, "rx")
最後の "rx" が赤 ('r'ed) の X 印 (x) を示しています。
ですが、軸がぎりぎりになってしまい、点が右上と左下に隠れてしまいました。 (赤い矢印で示したところにあります)
そこで、x, y の範囲をどちらも 0 - 4 に設定してみます。
pylab.xlim(0, 4) pylab.ylim(0, 4)
これで、正しく表示されるようになりました。
一度表示をクリアする場合は、以下のコマンドを呼びます。
pylab.clf()
もっと一気にたくさん点を描画してみます。 先ほど二次元の乱数を生成したので、それを plot してみます。
A = numpy.random.multivariate_normal([0,0],[[1,2],[2,1]],100)
for x,y in A:
plot(x,y,"go")
こんな感じになりました。
PyLab で線を描画してみる
これまでは点だけの描画でしたが、点をつないで線を描いてみます。
使い方は、先程の plot に配列を入れるだけです。
以前は plot(x座標, y 座標) だったので、plot(X 配列, Y 配列) に変わります。
"g-" は、緑 ('G'reen) で線でつなぐことを示しています。 なお、一つしか配列を指定しないと、その配列は Y 座標とみなされて、 自動的にX 座標は補完されるようです。
以前は plot(x座標, y 座標) だったので、plot(X 配列, Y 配列) に変わります。
X = range(-10,10) Y = [i * i for i in X] pylab.plot(X,Y,"g-")こんな感じになりました。
"g-" は、緑 ('G'reen) で線でつなぐことを示しています。 なお、一つしか配列を指定しないと、その配列は Y 座標とみなされて、 自動的にX 座標は補完されるようです。
PyLab で使える色
pyplot.py を見ると、以下が定義されています。
'b' blue 'g' green 'r' red 'c' cyan 'm' magenta 'y' yellow 'k' black 'w' whiteまた、html の色名 ('red' 'burlywood' 'chartreuse' など) も指定できるようです。 その場合、マーカーのタイプはどうやって指定すればいいの? というと、 以下のように指定できます。
pylab.plot(x, y, color='red', marker='o')ヘルプは、以下のように見ることができます。
print pylab.plot__doc__
観測した分布が予測した分布にあっているのか知りたい
仮説検定とか、カイ二乗検定とか呼ばれる手法です。
Wikipedia の記事がわかりやすいので、出ている例を引用します。
いくつかの他の値でも試してみます。
- ある集団は、男が 55 人、女が 45 人いる
- この集団が、男と女が同数だけいる集団から、ランダムに抽出された100人であるという仮説を立てた
- この仮説が正しい確率を知りたい
- 仮説を立てて、仮説での度数分布を計算する。この場合、仮説に基づくと男50人、女50人になる
- χ(カイ, chi) を計算する。χ = Σ(observed - expcted)^2 / expected として計算する
- 自由度 k のχ二乗分布を参照して、先ほど得られたχが観測される確率 p を調べる
- p が有意水準よりも大きければ仮説が妥当、小さければ妥当ではないと判断する (通例 0.05 = 5%)
import scipy.stats # 観測データ observed = np.array([55, 45]) # 仮説データ expected = np.array([50, 50]) # カイ二乗値 x2,p = scipy.stats.chisquare(observed, expected)ここで、x2 がカイ二乗値、p が確率となります。x2 = 1.0, p = 0.32 と出るので、 仮説が正しい時にこのような観測値が出る確率は 32% ということになります。 これは有意水準 5% よりも大きいので、この仮説は妥当だということになります。
いくつかの他の値でも試してみます。
>>> scipy.stats.chisquare(numpy.array([6,4]),numpy.array([5,5])) (0.4..., 0.52...)男 6 人、女 4 人の場合は、確率が 52% になりました。 このくらいのばらつきは大いに有り得る、ということですね。
>>> scipy.stats.chisquare(numpy.array([550,450]),numpy.array([500,500])) (10,0, 0.0015...)男 550 人、女 450 人の場合は、確率が 0.15% になってしまいました。 この場合は、元々男女が同数、という仮定が疑わしいことが分かります。
観測した分布が正規分布にあっているのか知りたい
先ほどの応用です。
しばしば、ある分布が正規分布だという仮定をしますが、それを実測値から検証してみます。
まずは手法を示します。
- 観測値から、平均、分散を計算して、検定先の正規分布を推定する
- 標本値を度数分布に変換する。k = (度数分布数 - 1) が自由度になる
- 期待される度数分布を、予測した正規分布から計算する
- あとは先の仮説検定を利用して評価する
k-means と ward でクラスタリング
scipy には、クラスタリングのアルゴリズムもいくつか実装されています。
ここでは階層的な ward 法と、非階層的な k-manes 法を試してみます。
サンプルにするのはこんなデータです。
サンプルにするのはこんなデータです。
(0,0) (0,1) (100,100) (101,101)それぞれ x.y 座標だと考えてみると、最初の 2 つと後半の 2 つがペアになるのが想像できます。
ward 法でクラスタリング
では、まずは ward 法のプログラムはこんな感じです。
import numpy
import scipy.cluster.vq
import scipy.cluster.hierarchy
data = [[0,0],[0,1,],[100,100],[101,101]]
A = numpy.array(data)
# クラスタリングは以下の 1 行だけ。
result_w = scipy.cluster.hierarchy.ward(A)
# 結果はツリー状なので、最後の 2 つを表示する
print result_w
elems=data[:]
for a, b, distance, represent in result_w:
elems.append((elems[int(a)], elems[int(b)]))
print elems[-2], elems[-3]
ward の実行結果は、こんな感じの配列になっています。
[[ 0. 1. 1. 2. ] [ 2. 3. 1.41421356 2. ] [ 4. 5. 200.50062344 4. ]]このデータの読み方ですが、1 行あたり 2 つの結び目になっています。
- 0 と 1 がペア。距離は 1。要素は 2 個。
- 2 と 3 がペア。距離は 1.414。要素は 2 個。
- 4(0,1) と 5 (2,3) ペア。距離は 0.14。要素は 2 個。
k-means 法でクラスタリング
次は k-means です。これは n クラスタに分けるとはじめから指定する必要があります。
初期値をランダムに選ぶので、データによっては実行するたびに結果が変わります。
import numpy import scipy.cluster.vq import scipy.cluster.hierarchy data = [[0,0],[0,1,],[100,100],[101,101]] A = numpy.array(data) result_k = scipy.cluster.vq.kmeans(A, 2) # 2 クラスタに分けるという意味 print result_kこれだけです。 結果はこんな感じで出ます。
(array([[ 0, 0],
[100, 100]]), 0.60355339059327373)
参考にしたサイト
- 正規分布への適合率の検定 http://aoki2.si.gunma-u.ac.jp/lecture/GoodnessOfFitness/normaldist.html
- http://ogawas.cerp.u-toyama.ac.jp/e-stat/kai.html
- http://www.lfd.uci.edu/~gohlke/pythonlibs/