OS上でのmmap()の実装・効率化
基本的な動作
mmapの基本的な動作はファイルをメモリにマップすることですが、mmap()を実行したときにいきなりファイルがメモリにコピーされるわけではありません。
mmap()を実行するとアドレスが返されますが、このときこのメモリ番地は物理メモリ上に乗っていません。
だから、この番地をアクセスするとページフォルトが発生します。このページフォルトを受けて、はじめてデータがファイル(ディスク)から物理メモリにコピーされます。(なお、もし元々このファイルがファイルキャッシュに乗っている場合は、このファイルキッシュのアドレスがそのまま返されます) mmapされた領域に書き込まれたデータは、適宜ディスクに書き戻されます。
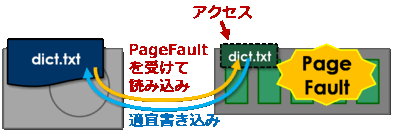
なお、ファイルの一部だけがアクセスされたら、その一部だけをメモリに乗せればよいです。また、物理メモリが足りなくなったら、あまりアクセスされていないページはページアウトさせます。
なお、ファイルの一部だけがアクセスされたら、その一部だけをメモリに乗せればよいです。また、物理メモリが足りなくなったら、あまりアクセスされていないページはページアウトさせます。
仮想メモリ・ページファイルとほとんど同じ
この「ページフォルトを受けてディスク上のファイルからデータを読み込む」というmmapの動作は、実はスワップファイル(ページファイル)を用いた仮想記憶のデータとほとんど同じです。違いは、ファイルをスワップファイルから読み込むか、ユーザが指定したファイルから読み込むかという部分だけです。だから、実際の処理も共通化されています。

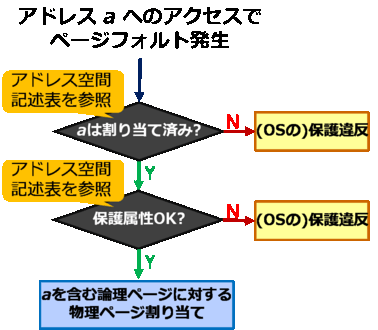
流れ図にするとこんな感じになります。まずはページフォルト処理です。 アドレスaにアクセスしたとき、このページが物理メモリ上に無いと、ハードウェア割り込みが発生します。 OSはこれを受けて、まずはそのアドレス(a)が割り当て済みかどうかをチェックします。 さらに、保護属性(読み込み専用とかアクセス不可とか)が正しければ物理メモリを割り当てようとします。
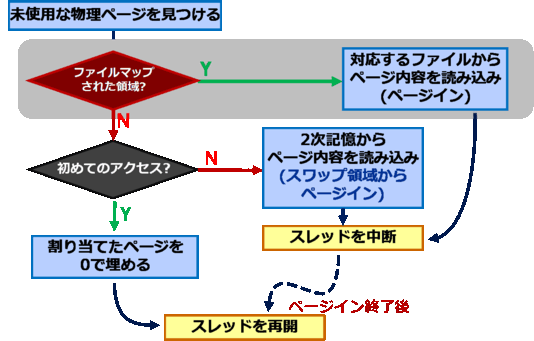
物理メモリの割り当て手順を次に示します。赤い「ファイルマップされた領域かどうか」という分岐と、それからつながる 指定されたファイルからページインする処理が、mmap()のために付け加わった処理です。こうして見ると、mmap()が 一般的なメモリ割り当てに用いられている理由が少しわかると思います。
流れ図にするとこんな感じになります。まずはページフォルト処理です。 アドレスaにアクセスしたとき、このページが物理メモリ上に無いと、ハードウェア割り込みが発生します。 OSはこれを受けて、まずはそのアドレス(a)が割り当て済みかどうかをチェックします。 さらに、保護属性(読み込み専用とかアクセス不可とか)が正しければ物理メモリを割り当てようとします。
物理メモリの割り当て手順を次に示します。赤い「ファイルマップされた領域かどうか」という分岐と、それからつながる 指定されたファイルからページインする処理が、mmap()のために付け加わった処理です。こうして見ると、mmap()が 一般的なメモリ割り当てに用いられている理由が少しわかると思います。
プライベートマッピングと共有マッピング
APIのセクションで、複数のプロセスがファイルをmmapするときの方法に、
プライベートマッピングと共有マッピングがあると書きました。
ここで両者の実装を考えてみると、共有マッピングが大変効率良くメモリを使えるのに対し、
プライベートマッピングは単純な実装だとメモリを多く使ってしまいます。
下に簡単な対比図を示します。
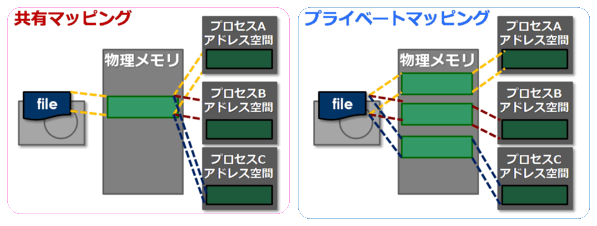
共有マッピングだと、各プロセスはアドレス空間は別々でも、実際には同じ物理メモリを共有できます。 さらにこれはディスク上のデータとも意味上同一なので、ファイルキャッシュとも共有することができます。 つまり、既に他のプロセスがアクセスしたことによりメモリ上にあるデータはページフォルトを起こすことなく mmap()により(コピーコスト無しで)共有することができるし、mmap以外の方法によってアクセスされてファイルの内容が キャッシュされているときもそのまま参照することができます。
これに対し、プライベートマッピングの場合は各プロセスが別々の領域を必要とします。 結果として、単純な実装ではマッピングの数だけ物理メモリを消費してしまいます。 複数のコピーを作るためにはメモリコピーが発生します。 つまり、ファイルがキャッシュされていてもそこから別の物理メモリにコピーすることが必要です。 これは、書き込まれたときにその結果が他のプロセスおよびディスクに反映されないようにするために必要です。
共有マッピングだと、各プロセスはアドレス空間は別々でも、実際には同じ物理メモリを共有できます。 さらにこれはディスク上のデータとも意味上同一なので、ファイルキャッシュとも共有することができます。 つまり、既に他のプロセスがアクセスしたことによりメモリ上にあるデータはページフォルトを起こすことなく mmap()により(コピーコスト無しで)共有することができるし、mmap以外の方法によってアクセスされてファイルの内容が キャッシュされているときもそのまま参照することができます。
これに対し、プライベートマッピングの場合は各プロセスが別々の領域を必要とします。 結果として、単純な実装ではマッピングの数だけ物理メモリを消費してしまいます。 複数のコピーを作るためにはメモリコピーが発生します。 つまり、ファイルがキャッシュされていてもそこから別の物理メモリにコピーすることが必要です。 これは、書き込まれたときにその結果が他のプロセスおよびディスクに反映されないようにするために必要です。
Copy-on-writeによるプライベートマッピングの効率化
プライベートマッピングでは各プロセスが意味上別々のメモリを持つため、単純な実装では
コピーが必要です。
しかし、これらのメモリは必ずしも全部が書き換えられるわけではありません。
そうであれば、初めは物理メモリを共有しておき、必要なときに初めてコピーするという手法が考えられます。
これがCopy-on-writeというテクニックです。
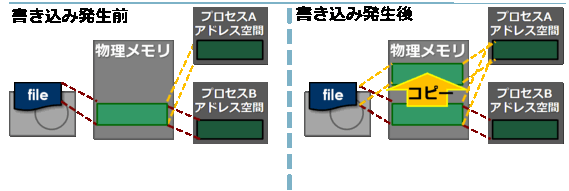
これはどちらもプライベートマッピングの図ですが、左の図は前の共有マッピングとほぼ同じです。 あるファイルがプライベートでmmap()されてアクセスが発生しても、初めはコピーを行わず、ディスクキャッシュや 他のプロセスがmmapしている領域を参照するようにします。同時にこの領域をOSのプロテクトモードで「書き込み不可」 にしておきます。そして、実際に書き込みが起こったときにOSがそれを保護違反として検出し、コピーと ページテーブル(物理メモリのアドレス空間の対応表)の書き換えを行います。もしも書き込みが起こらなければ、 コピーは一度も行われません。
このようなCopy-on-writeのテクニックは、処理系の実装ではしばしば見られます。 fork()時に親プロセスと子プロセスで使うメモリ空間を独立なものにするために用いられたり、 PHPやPythonで値渡しの大きな変数(stringやリスト)に対して用いられたりします。
これはどちらもプライベートマッピングの図ですが、左の図は前の共有マッピングとほぼ同じです。 あるファイルがプライベートでmmap()されてアクセスが発生しても、初めはコピーを行わず、ディスクキャッシュや 他のプロセスがmmapしている領域を参照するようにします。同時にこの領域をOSのプロテクトモードで「書き込み不可」 にしておきます。そして、実際に書き込みが起こったときにOSがそれを保護違反として検出し、コピーと ページテーブル(物理メモリのアドレス空間の対応表)の書き換えを行います。もしも書き込みが起こらなければ、 コピーは一度も行われません。
このようなCopy-on-writeのテクニックは、処理系の実装ではしばしば見られます。 fork()時に親プロセスと子プロセスで使うメモリ空間を独立なものにするために用いられたり、 PHPやPythonで値渡しの大きな変数(stringやリスト)に対して用いられたりします。