ファイルとメモリ
OSによるディスクとメモリの抽象化
今お店で売っているコンピュータは、性能の違いを除けばどれも同じように使えます。
Windowsを買ってきて(あるいはLinuxをダウンロードして)、ブラウザとかメールソフトとかを入れれば
ハードウェアの違いは意識することがありません。
でも実際には、コンピュータによってメモリのチップ、ディスクの容量、数、ネットワークカードのメーカーや仕様などは大きく異なっています。こうした差異を吸収してくれているのがOS (オペレーティングシステム)です。OSは色々な資源を抽象化し、プログラマは一種類のプログラムを書きさえすれば、どんなハードウェアでも実行できるようにしてくれます。しかも、メモリがたくさんある環境では高速に、メモリがあまりない環境でも「とりあえずは動く」ように色々と工夫をしてくれます。
実際のハードウェアとOSによる抽象化の例をまとめてみたのが下の図・表です。
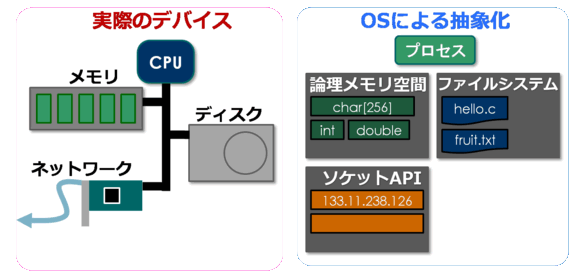
論理アドレス空間とは、プログラムを実行したときに見えるメモリアドレスの空間です。 (論理アドレス空間についてまだ知らない人は、Wikipedia:仮想記憶などを参照してみてください) 一応メモリは「論理メモリ空間(アドレス空間)」に、ディスクは「ファイルシステム」に対応しています。でも、必ずしも「アドレス空間は必ずメモリ」「ファイルは必ずディスク」と決まっているわけではなく、OSは柔軟にディスクとメモリを使い分けます。次は、この使い分けについて見てみます。
実際のハードウェアとOSによる抽象化の例をまとめてみたのが下の図・表です。
| ハードウェア デバイス | CPU | メモリ | ディスク | ネットワーク |
|---|---|---|---|---|
| OSの見せ方 | プロセス スレッド |
論理アドレス空間 変数 |
ファイルシステム ファイル |
TCP/IP ネットワーク |
論理アドレス空間とは、プログラムを実行したときに見えるメモリアドレスの空間です。 (論理アドレス空間についてまだ知らない人は、Wikipedia:仮想記憶などを参照してみてください) 一応メモリは「論理メモリ空間(アドレス空間)」に、ディスクは「ファイルシステム」に対応しています。でも、必ずしも「アドレス空間は必ずメモリ」「ファイルは必ずディスク」と決まっているわけではなく、OSは柔軟にディスクとメモリを使い分けます。次は、この使い分けについて見てみます。
メモリとディスク
メモリとディスクはコンピューターの二大記憶装置です。どちらもデータをためておく場所なのですが、それぞれ長所、短所があるので、どちらかに一本化するわけにはいきません。それぞれの特徴を簡単にまとめてみます。
メモリは高速なので、頻繁にアクセスするデータを置いておくのに適します。 一方でディスクは広大な領域を必要とするデータに適します。
OSはメモリとディスクを「論理アドレス空間」「ファイル」という形で抽象化しますが、 いずれも「メモリだけ」「ディスクだけ」使うのではなく、両者を組み合わせていいとこ取りを しています。以下、その例を見てみます。
| ディスク | アクセスは遅い | 安価・大容量 | 電源を切ってもデータは消えない |
|---|---|---|---|
| (物理)メモリ | アクセスは速い | 高価・小容量 | 電源を切るとデータが消える |
メモリは高速なので、頻繁にアクセスするデータを置いておくのに適します。 一方でディスクは広大な領域を必要とするデータに適します。
OSはメモリとディスクを「論理アドレス空間」「ファイル」という形で抽象化しますが、 いずれも「メモリだけ」「ディスクだけ」使うのではなく、両者を組み合わせていいとこ取りを しています。以下、その例を見てみます。
仮想メモリ
仮想メモリは、ディスクを用いて実際の物理メモリより大きなメモリ空間を実現する手法です。
物理メモリはハードウェアで容量が1GBとか2GBとかいう風に容量が決まっています。 でも、実際に一度に2GBを常にアクセスしていることは多くなく、多くの領域はデータを置いてしばらく 放って置かれています。メモリが1GBしか無いマシンで2GBのメモリを使いたい場合、 これらの「今は使われていない」データを適宜ディスクに逃がしてやれば、あたかもメモリが2GBあるのと同じように動いてしまいます。これが仮想記憶(仮想メモリ)です。
仕組みとしては、実際のメモリよりも広大な仮想アドレス空間があって、その一部はディスク上のスワップファイルに載っています。アクセスしたアドレスが物理メモリ上に無い場合、「ページフォルト」が発生し、ディスク上のスワップファイルからデータが読み出されます。
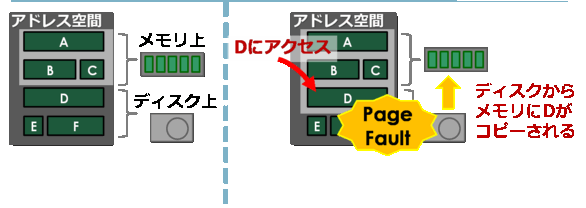
物理メモリはハードウェアで容量が1GBとか2GBとかいう風に容量が決まっています。 でも、実際に一度に2GBを常にアクセスしていることは多くなく、多くの領域はデータを置いてしばらく 放って置かれています。メモリが1GBしか無いマシンで2GBのメモリを使いたい場合、 これらの「今は使われていない」データを適宜ディスクに逃がしてやれば、あたかもメモリが2GBあるのと同じように動いてしまいます。これが仮想記憶(仮想メモリ)です。
仕組みとしては、実際のメモリよりも広大な仮想アドレス空間があって、その一部はディスク上のスワップファイルに載っています。アクセスしたアドレスが物理メモリ上に無い場合、「ページフォルト」が発生し、ディスク上のスワップファイルからデータが読み出されます。
ファイルキャッシュ
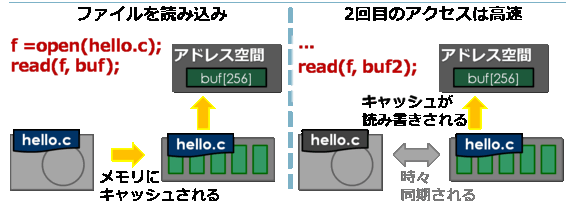
ファイルキャッシュは、メモリを用いてディスクを高速に用いる方法です。
ディスクのよくアクセスされる領域をメモリ上に置き、読み書きはこのキャッシュに対して行います。
ただ、それだけだと電源を切ったときにデータが消えてしまうので、適宜書き込みも行います。
こうすることで、ディスクの大容量性や不揮発性(データが消えないこと)を残しつつ、2回目のアクセスからは高速に用いることが出来ます。
メモリとファイルのAPI
このようにOSではファイルとメモリという抽象化を用いて、
ディスクと物理メモリを相互補完させて使いやすい仕組みを作っています。
典型的なファイルとメモリの使い方は以下の通りです。
これに対し、メモリはランダムアクセスが得意です。複雑なリンク構造を作っても、簡単にアクセスできます。一方でメモリ上のデータは他のプロセスが読んだり、人間が読むのには適しません。使っては解放し、を繰り返したメモリ空間は必要なデータが散乱してしまっているので、そのまま保存しておくのには向きません。
簡単にファイルとメモリのAPIをまとめると、以下のようになります。
- ファイル: 整理したデータ置き場
- メモリ: 一時的なデータ置き場
これに対し、メモリはランダムアクセスが得意です。複雑なリンク構造を作っても、簡単にアクセスできます。一方でメモリ上のデータは他のプロセスが読んだり、人間が読むのには適しません。使っては解放し、を繰り返したメモリ空間は必要なデータが散乱してしまっているので、そのまま保存しておくのには向きません。
簡単にファイルとメモリのAPIをまとめると、以下のようになります。
| - | 開く | 読み込み | 書き込み |
|---|---|---|---|
| メモリ | malloc(128); int A[10]; |
i; A[2]; |
i = 10; A[10] = 128; |
| ファイル | open() | read() seek() |
write() seek() |
ファイルをランダムアクセスするプログラムを書いてみる
先ほど言ったように、ファイルのAPIはランダムアクセスに向きません。
でも、場合によってはファイルをランダムアクセスしたい場合もあります。
例えば、辞書のような大きなファイルの色んなところを必要に応じて読む場合を考えてみます。 もしファイルが一気にメモリに載せられるほど大きくない場合、malloc()してseek()してread()して、 を何度も繰り返す必要があります(下図の左)。もしファイルがメモリみたいに操作できたら、 この操作はずっと簡単になります(下図の右) これを実現するのがmmap()です。
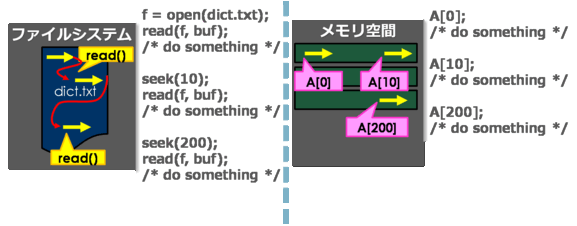
例えば、辞書のような大きなファイルの色んなところを必要に応じて読む場合を考えてみます。 もしファイルが一気にメモリに載せられるほど大きくない場合、malloc()してseek()してread()して、 を何度も繰り返す必要があります(下図の左)。もしファイルがメモリみたいに操作できたら、 この操作はずっと簡単になります(下図の右) これを実現するのがmmap()です。