[an error occurred while processing this directive]
[an error occurred while processing this directive]
暲楍暘嶶僔僗僥儉傪婰榐偡傞
戝婯柾側僔僗僥儉偵偼僩儔僽儖偑偮偒傕偺偱偡丅
偙偆偟偨僩儔僽儖偵懳張偡傞婎杮偼丄搑拞偺寁嶼寢壥偺僶僢僋傾僢僾傪庢偭偰偍偔
偙偲偱偡丅掕婜揑偵僶僢僋傾僢僾傪庢偭偰偍偗偽丄僩儔僽儖偺尨場夝愅傗
寁嶼傪傗傝捈偡庤娫偑徣偗傑偡丅
偲偼偄偊丄暲楍僔僗僥儉偱偼揔摉偵曐懚偟偰偄傞偩偗偱偼梋傝栶偵棫偪傑偣傫丅
奺僾儘僙僢僒偑偽傜偽傜偵曐懚偟偰傕丄奺僾儘僙僢僒偺僋儘僢僋偼偽傜偽傜側偺偱
偳偺忬懺偲偳偺忬懺偑懳墳偟偰偄傞偺偐偑暘偐傝傑偣傫丅傑偨丄僾儘僙僢僒娫傪
堏摦偟偰偄傞儊僢僙乕僕偑偁偭偨応崌丄偙偺僨乕僞傪偳偆埖偆偐傕擄偟偄栤戣偱偡丅
忦審暘婒傕孞傝曉偟傕側偔丄傂偨偡傜恑傓僾儘僌儔儉側傜丄僾儘僌儔儉傪彂偔抜奒偱
曐懚偡傞億僀儞僩傪巜掕偡傞偙偲偑偱偒傑偡偑丄暋嶨側暘婒傪帩偮僾儘僌儔儉偱偼
偦傟傕擄偟偔側傝傑偡丅
偙偙偱偼丄僔僗僥儉慡懱偺條巕傪婰榐偡傞偺傪栚昗偲偟偰丄棟榑揑側峫嶡傪峴偄傑偡丅
棳傟偼
- Local State, Global State, Consistency, Cut側偳偺尵梩傪掕媊偡傞
- 忬懺偺婰榐偵偍偗傞栤戣揰傪巜揈偡傞
- Chandy-Lamport偺Global State傪婰榐偡傞傾儖僑儕僘儉傪帵偡
偲側傝傑偡丅側偍丄偙偙偱傕帪崗偼慡偰vector clock傪梡偄偰偄傑偡丅
怓傫側尵梩偺掕媊
Local State, Global State
Local State偲偼丄奺僾儘僙僢僒偑帩偮忬懺偺偙偲偱偡丅
偙偺Local State傪奺僾儘僙僢僒偵偮偄偰廤傔偨傕偺偑
Global State偱偡丅
偁傞Global State偑僾儘僙僢僒Pi偺僀儀儞僩e傪娷傓偲偼丄
Global State偑Pi偺Local State傪娷傒丄偐偮偦偺Local State偑
e偺屻偵婰榐偝傟偨傕偺偱偁傟偽偄偄偱偡丅
儊僢僙乕僕偺忬懺
偙偙偱偼丄儊僢僙乕僕偺憲庴怣偺僞僀儈儞僌傪栤戣偵偡傞偺偱丄
偙傟傪昞偡婰朄傪摫擖偟傑偡丅
- time(x)僀儀儞僩x偑婲偒偨帪崗(Vector Clock)
- send(m)乧m傪憲傞僀儀儞僩
- recv(m)乧m傪庴怣偡傞僀儀儞僩
偙偙偱丄偁傞儊僢僙乕僕偵偮偄偰丄憲怣偼昁偢庴怣傛傝傕愭偵婲偙傝傑偡丅
側偺偱丄time(send(m)) < time(recv(m))偑惉棫偟傑偡丅
傑偨丄儊僢僙乕僕偺憲怣懁偲庴怣懁偺擇偮偺僾儘僙僢僒偺Local State傪
娷傓Global State偵偮偄偰丄
- send(m)傪娷傒丄recv(m)傪娷傑側偄乧Transit(憲怣拞)
- recv(m)傪娷傒丄send(m)傪娷傑側偄乧Inconsistent(晄惍崌)
- inconsistent側儊僢僙乕僕偑柍偄乧Consistent
- transit側儊僢僙乕僕偑柍偄乧Transitless
- transitless偱丄偐偮consistent乧Strongly Trnasitless
偲掕媊偟傑偡丅
偙偙偱拲堄偡傞偺偼丄transitless側忬懺偼inconsistent偱傕椙偄丄
偲偄偆偙偲偱偡丅扨側傞掕媊偺栤戣偱偡偑丅
偳偆偄偆晽偵栶偵棫偮偐
忬懺傪婰榐偡傞応崌丄杮摉偼慡僾儘僙僢僒偵偮偄偰幚帪娫偑摍偟偄偺偑
朷傑偟偄偺偱偡偑丄偦傟偼側偐側偐曐徹偱偒傑偣傫丅
偟偐偟丄inconsistent側儊僢僙乕僕偑柍偗傟偽丄
(Causal Ordering of events偑曐徹偝傟傟偽)
傕偟摨帪偵婲偙偭偨偲偟偰傕丄偍偐偟偔偁傝傑偣傫丅
媡偵inconsistent側儊僢僙乕僕偑偁傟偽丄偦偺Global State偼
幚帪娫忋偱摨帪偵偼婲偙傝偊傑偣傫丅
傑偨丄transit側儊僢僙乕僕偑偁偭偨応崌偼丄僾儘僙僢僒偺忬懺傪婰榐偡傞偩偗偱偼
忣曬偑懌傝傑偣傫丅偙偆偄偆帪偼丄儊僢僙乕僕偺憲怣楬傪娔帇偡傞偐丄
Transit側儊僢僙乕僕偑摓拝師戞婰榐偟丄僾儘僙僢僒偺忬懺偵崌傢偣傞偙偲偱
姰慡側忬懺傪婰榐偡傞偙偲偑偱偒傑偡丅
Cut偲偟偰尒傞(嶲峫)
Global State偼丄Local State傪node偲偡傞僌儔僼(帪娫幉忋偵峀偑偭偰偄傞)
偺Cut(愗抐)偲偟偰尒傟傞傛偆偱偡丅
偦偆偡傞偲丄Inconsistent State傗Transit State偼丄偙偺Cut偲儊僢僙乕僕偺
岎揰偺桳柍偱挷傋傞偙偲偑偱偒傞傛偆偱偡丅
幚椺傪尒偰傒傞
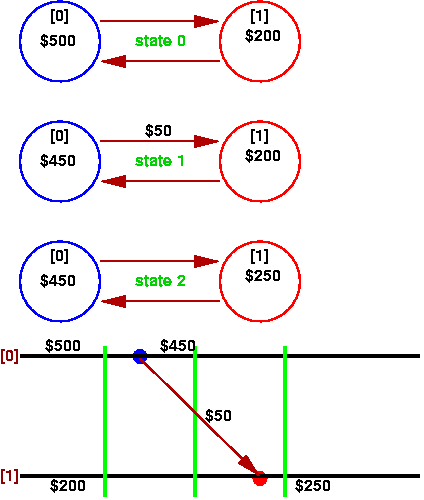
椺偊偽丄壓恾偺傛偆側僔僗僥儉傪峫偊傑偡丅
A偲B偼嬧峴偺岥嵗偑壗偐偱丄偍屳偄僱僢僩儚乕僋偱
忣曬傪傗傝偲傝偱偒傑偡丅
state0偱偼A偼$500, B偼$200帩偭偰偄傑偡偑丄
state1偱A偼B偵$50憲嬥偟傑偡丅
憲嬥偟偨$50偼丄state 2偱摓拝偟傑偡丅
偙偺僔僗僥儉傪婰榐偡傞帪丄婲偙傝摼傞働乕僗傪峫偊偰傒傑偡丅
偙偺応崌丄[0], [1]媦傃憲怣拞偺儊僢僙乕僕傪婰榐偟偰
崌寁偡傟偽丄偦偺抣偼忢偵$700偱堦掕偱偁傞傋偒偱偡丅
椺偊偽丄
- state 0 偺[0], state 0 偺儊僢僙乕僕, state 0 偺[1](Stlongly Transitless)
- state 1 偺[0], 儊僢僙乕僕, [1](Consistent)
- state 2 偺[0], 儊僢僙乕僕, [1](Stlongly Transitless)
偺偦傟偧傟傪崌傢偣偨Global State傪峫偊傟偽丄偙傟傜偺崌寁偼偪傖傫偲
$700偵側傝傑偡丅
偟偐偟丄埲壓偺傛偆側慻傒崌傢偣偱偼丄崌寁偑$700偵側傝傑偣傫丅
- state 0 偺[0], State 1 偺儊僢僙乕僕, State2偺[1](inconsistent)
- state 2 偺[0], Stete 1 偺儊僢僙乕僕, State0偺[1](transit)
偙偺傛偆偵丄偪傖傫偲崌寁傪媮傔傞偨傔偵偼丄
憲怣拞偺儊僢僙乕僕傕僇僂儞僩偱偒傞応崌偼Consistent丄
偱偒側偄応崌偼Strolgly Consistent偱偁傞昁梫偑偁傞偙偲偑暘偐傝傑偡丅
偙偺椺偱傕暘偐傞傛偆偵丄Global State偺拞偱傕Consistent側傕偺埲奜偼埖偄偵偔偔丄
婰榐偡傞応崌偼Consistent側忬懺傪婰榐偟偨偄丄偙偲偑暘偐傝傑偡丅
Chandy-Lamport偺Global State傪婰榐偡傞傾儖僑儕僘儉傪帵偡
偙偺傾儖僑儕僘儉偼丄Global State傪娙扨偵婰榐偡傞傕偺偱偡丅
Consistent側Global state傪婰榐偡傞丄椺偊偽僔僗僥儉拞偺偁傞抣偺
崌寁傪媮傔傞丄偲偄偭偨傛偔巊傢傟傞憖嶌偺偨傔偵
堦乆慡偰偺儊僢僙乕僕偵偮偄偰strolgly transitless偱偁傞偙偲傪帵偡偺偼戝曄偱偡丅
偙偺偨傔丄Global State偺棟榑揑棤晅偗傪帩偨偣偮偮丄娙扨偵崌寁傪媮傔傜傟傞
曽朄偲偟偰丄Chandy-Lamport偺傾儖僑儕僘儉傪愢柧偟傑偡丅
掕媊
偙偺傾儖僑儕僘儉偱偼丄
儅乕僇乕偲偄偆摿暿側儊僢僙乕僕傪梡偄傑偡丅
側偍丄偙偺僔僗僥儉偱偼憲怣偟偨儊僢僙乕僕偼憲偭偨弴偵摓拝偟丄
憲偭偨儊僢僙乕僕偑搑拞偱幐傢傟傞偙偲偼側偄傕偺偲偟傑偡丅
傑偨丄憲怣楬偼慡僾儘僙僗娫偵偁傞傕偺偲偟傑偡丅
- 奺僾儘僙僗偼偁傞億僀儞僩偵擖傞偲丄尰嵼偺忬懺傪婰榐偡傞丅
偙傟偼堦戜偺僾儘僙僗偩偗偑婰榐傪偟偰傕偄偄偟丄彑庤偵暋悢偺僾儘僙僗偑
婰榐傪偟偰傕傛偄
- 忬懺傪婰榐偟偨僾儘僙僢僒偼丄慡偰偺憲怣楬偵"儅乕僇乕"偲偄偆
摿庩側儊僢僙乕僕傪憲傞丅
偙傟偼丄師偺儊僢僙乕僕傛傝愭偵憲傜側偔偰偼側傜側偄
- 儅乕僇乕傪庴偗庢偭偨僾儘僙僢僒偼丄傑偩帺暘偑忬懺傪婰榐偟偰偄側偗傟偽丄
"Empty Sequence"偲偟偰尰嵼偺忬懺傪婰榐偡傞丅
婰榐偟偨屻偼丄愭偺儖乕儖偵廬偆
傕偟儅乕僇乕傪庴偗庢偭偨僾儘僙僢僒偑婛偵尰嵼偺忬懺傪婰榐偟偰偄傟偽丄
婰榐偟偨帪偐傜儅乕僇乕傪庴偗庢偭偨帪傑偱偺儊僢僙乕僕傪婰榐偡傞丅
億僀儞僩偼丄婰榐偺堷偒嬥偲偟偰僟儈乕偺儊僢僙乕僕偱偁傞儅乕僇乕傪憲怣偟丄
Inconsistent側忬懺傪杊偄偱偄傞偙偲偱偡丅
傑偨丄婰榐屻偵摓拝偟偨儊僢僙乕僕傪捛壛偱婰榐偡傞偙偲偱
transit側儊僢僙乕僕傪偪傖傫偲悢偊楻傟側偄傛偆偵偟偰偄傑偡丅
幚椺
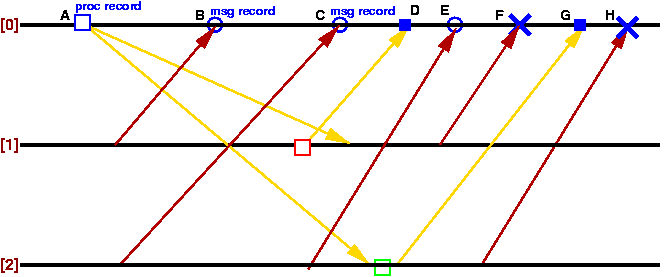
偙傟傕幚椺傪嫇偘偰傒傑偡丅
仩偑僾儘僙僗忬懺偺婰榐傪丄仜偑儊僢僙乕僕偺婰榐傪丄仭偑儅乕僇乕偺摓拝傪丄
亊偑儊僢僙乕僕偑婰榐偝傟側偐偭偨偙偲傪帵偟傑偡丅
側偍丄僾儘僙僗[0]埲奜偺儅乕僇乕傗儊僢僙乕僕偺婰榐偼徣偄偰偁傝傑偡丅
[0]偼A偱僾儘僙僗偺忬懺傪婰榐偟丄儅乕僇乕傪[1]偲[2]偵憲怣偟傑偡丅
偙偺偲偒丄[1]偼傕偆婰榐嵪傒偱偡偑丄[2]偼帺暘偺忬懺傪傑偩婰榐偟偰偄側偄偺偱丄
儅乕僇乕摓拝屻偡偖偵忬懺傪婰榐偟丄儅乕僇乕傪曉怣偟偰偒傑偡丅
(幚嵺偵偼[1]偐傜[2]丄[2]偐傜[1]傊傕儅乕僇乕偑憲怣偝傟傑偡)
僾儘僙僢僒[0]偱偼丄帺暘偺忬懺傪婰榐(A)偟偰偐傜
[1]偐傜偺儅乕僇乕偑棃傞傑偱偵摓拝偟偨丄
[1]偐傜偺儊僢僙乕僕傪婰榐(B)偟丄傑偨[2]偐傜偺儊僢僙乕僕偑棃傞傑偱偵
摓拝偟偨[2]偐傜偺儊僢僙乕僕傪婰榐(C,E)偟傑偡丅
F傗H偼丄傕偆儅乕僇乕傪庴偗庢偭偰偄傞偺偱丄儊僢僙乕僕偼婰榐偝傟傑偣傫丅